Commonsense Reasoning for Legged Robot Adaptation with Vision-Language Models
Abstract
Legged robots are physically capable of navigating a diverse variety of environments and overcoming a wide range of obstructions. For example, in a search and rescue mission, a legged robot could climb over debris, crawl through gaps, and navigate out of dead ends. However, the robot's controller needs to respond intelligently to such varied obstacles, and this requires handling unexpected and unusual scenarios successfully. This presents an open challenge to current learning methods, which often struggle with generalization to the long tail of unexpected situations without heavy human supervision. To address this issue, we investigate how to leverage the broad knowledge about the structure of the world and commonsense reasoning capabilities of vision-language models (VLMs) to aid legged robots in handling difficult, ambiguous situations. We propose a system, VLM-Predictive Control (VLM-PC), combining two key components that we find to be crucial for eliciting on-the-fly, adaptive behavior selection with VLMs: (1) in-context adaptation over previous robot interactions and (2) planning multiple skills into the future and replanning. We evaluate VLM-PC on several challenging real-world obstacle courses, involving dead ends and climbing and crawling, on a Go1 quadruped robot. Our experiments show that by reasoning over the history of interactions and future plans, VLMs enable the robot to autonomously perceive, navigate, and act in a wide range of complex scenarios that would otherwise require environment-specific engineering or human guidance.
VLM-PC in Challenging Real-World Scenarios
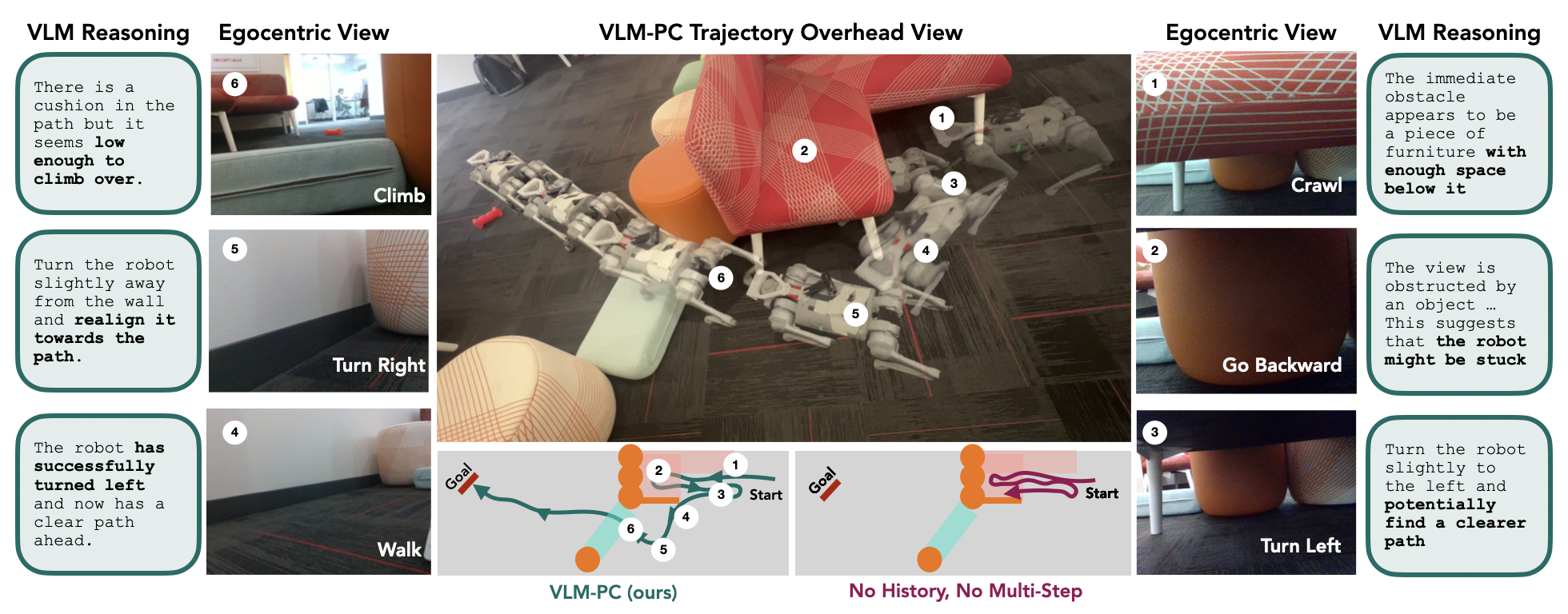
We evaluate our method, VLM-PC, on a Go1 quadruped robot across a variety of challenging real-world obstacle courses, involving dead ends and climbing and crawling. Each setting presents diverse unseen obstacles and varying terrain conditions and is designed for the robot to get stuck. As such, these settings require the robot to explore different strategies to make progress and make adjustments based on new information, thus necessitating commonsense reasoning to solve. The goal in each setting is to reach the “red chew toy”. The robot only receives information from its camera and does not have access to a map of the environment. On the left we highlight the challenges the robot faces in each scene and on the right we show how VLM-PC enables the robot to handle these scenarios fully autonomously.
Blocked Couch |
The robot has difficulty remembering that the couch is a dead end and continually moves back and forth under the couch. With VLM-PC, the robot is able to try different actions based on the given scenario until it escapes the corner, using its previous actions to understand when it gets stuck and to try to get itself unstuck. |
Narrow Gap |
The robot gets stuck in a gap that is too small for its body and cannot figure out that it needs to back out and go around. VLM-PC retries moving in different directions after historical attempts make no progress. |
Unstable Step |
Due to the length of the incline and step, the robot can get caught in the middle of climbing the unstable step. With VLM-PC, the robot figures out to re-climb the step after reorienting itself. |
Bamboo + Bench |
The robot needs to understand it can't get through the bamboo, then turn and crawl under the bench to get to the chew toy. VLM-PC allows the robot to back up accordingly and reorient towards the red chew toy and successfully crawl under the bench. |
Bush |
The robot struggles to explore the space effectively to find the chew toy. With VLM-PC, the robot is able to effectively search to find its objective, checking the left area after the bushes seem unpromising. |
VLM Predictive Control (VLM-PC)
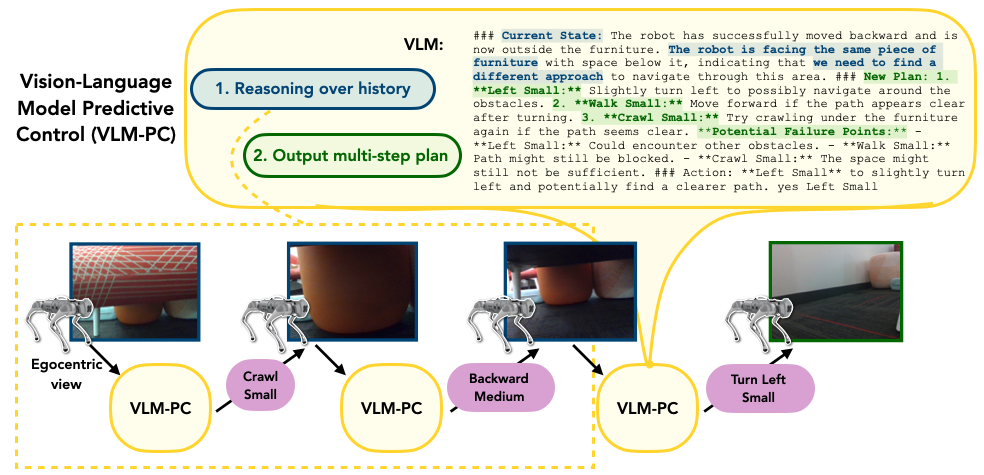
We propose VLM-PC, where we find two key insights help enable VLMs to serve as an effective high-level policy: (1) in-context reasoning about information gathered over previous interactions in the environment and (2) planning multiple skills into the future and replanning.
We evaluate our method along with the following comparisons:
- Random Action: Takes random (small) actions.
- No History: VLM-PC with planning, but with no history input.
- No Multi-Step: VLM-PC with full history, but no plan generation.
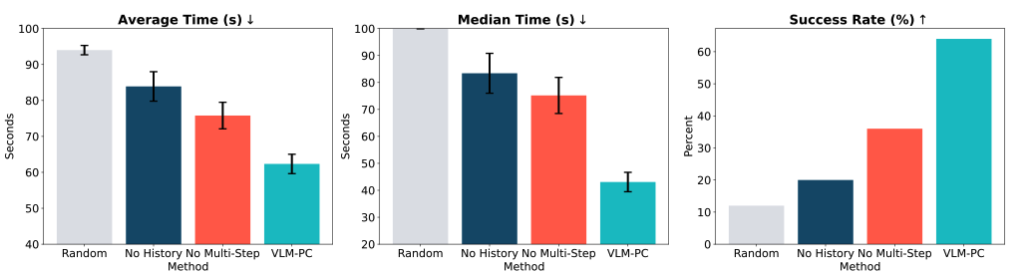
Below are our results averaged over trials in five challenging settings, where trials are cut off after 100 seconds of movement time, so any failures are counted as 100 seconds.
In-Context Examples Can Improve Performance
We provide an extension of our method including in-context examples called VLM-PC+IC, where we include in the first prompt several additional images, taken from the egocentric view at different points in the environment, as well as a label for each of them with the best command to take. We find that this can significantly improve the robot's performance, which further reinforces the importance of providing useful context to the VLM and having it use this context to make informed decisions.
In the Narrow Gap setting, adding 3 ICL examples leads to highly-efficient accomplishment of the goal.
In the Unstable Step setting, the robot successfully climbs the shaky step, avoiding even knocking against the step due to the in-context recommendations which we curated from just four examples.
Failures
VLM-PC sometimes fails even with planning and history, though enhancements of our basic method may improve its effectiveness.
In the Blocked Couch setting, sometimes the robot has difficulty navigating out of the corner due to lack of precise actions, as in our method we only provide actions at three common-language magnitudes (small, medium, large) rather than specific degree measurements or intended distances.
In the Unstable Step setting, the inherent instability of the step may result in a robot fall. Without any fall recovery skills, this leads to immediate failure on the overall task.